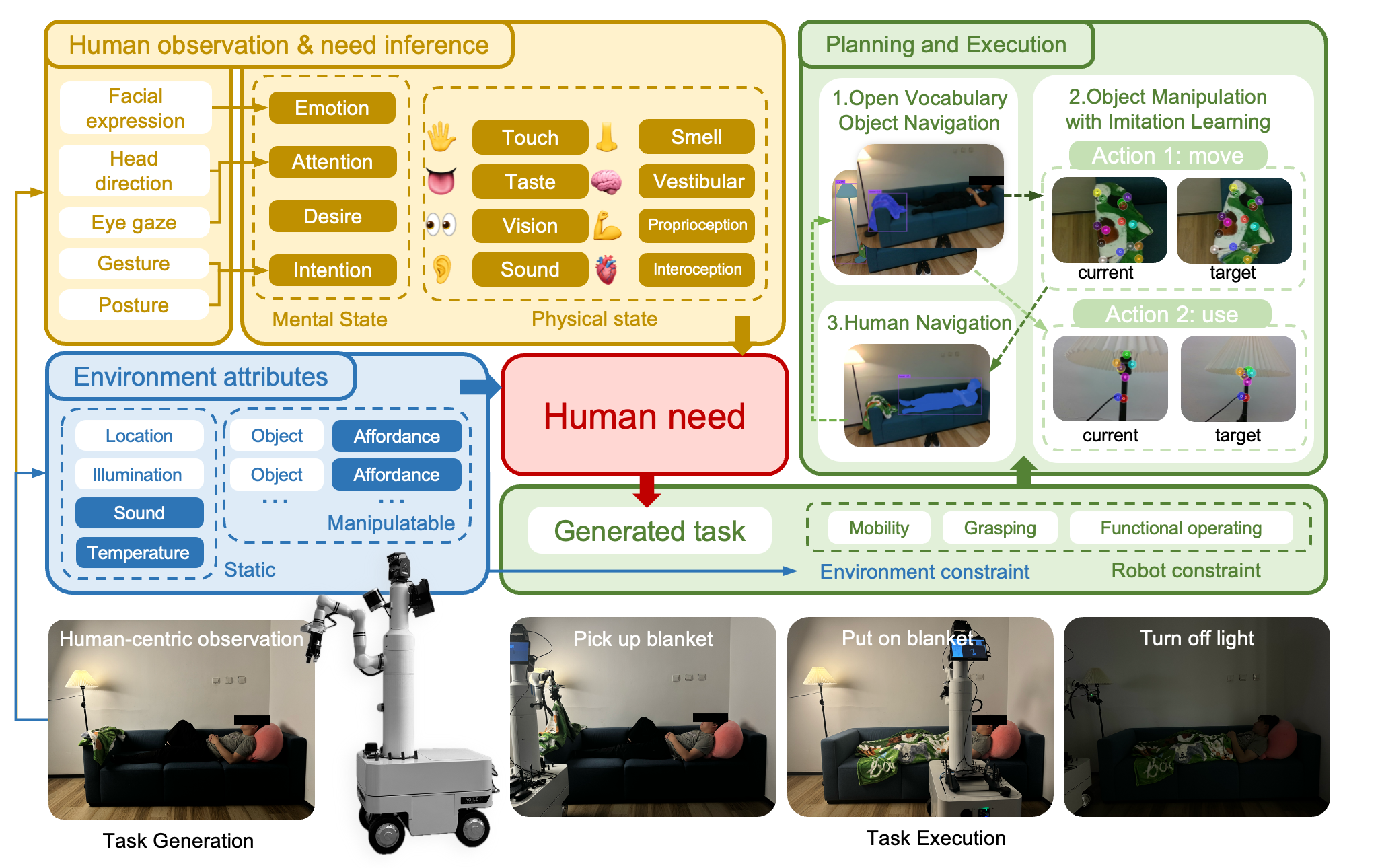
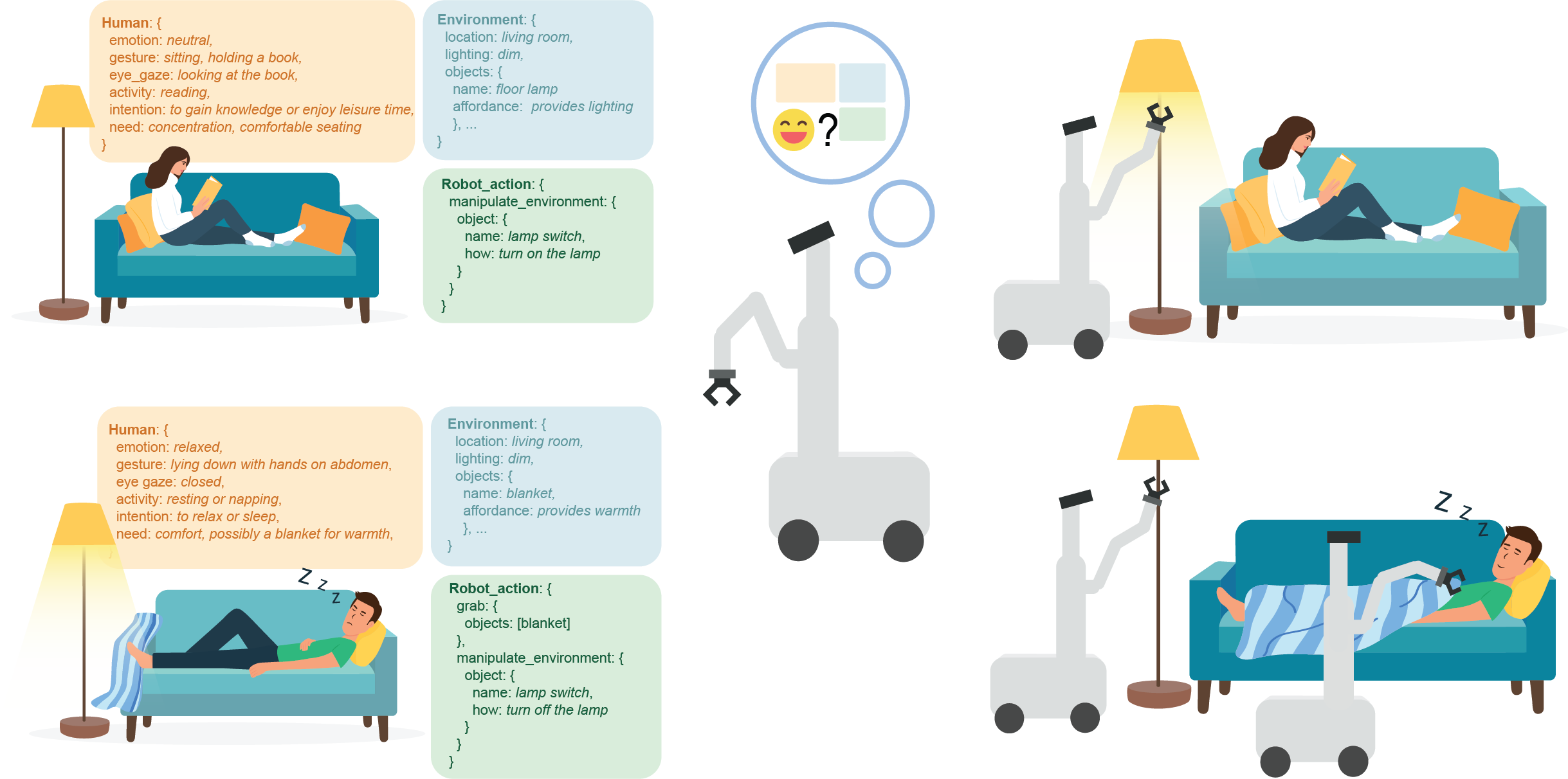
We propose AToM-Bot, a novel task generation and execution framework for proactive robot-human interaction, which leverages the human mental and physical state inference capabilities of the Vision Language Model (VLM) prompted by the Affective Theory of Mind (AToM). Without requiring explicit commands by humans, AToM-Bot proactively generates and follows feasible tasks to improve general human well-being. When around humans, AToM-Bot first detects current human needs based on inferred human states and observations of the surrounding environment. It then generates tasks to fulfill these needs, taking into account its embodied constraints. We designed 16 daily life scenarios spanning 4 common scenes and tasked the same visual stimulus to 59 human subjects and our robot. We used the similarity between human open-ended answers and robot output, and the human satisfaction scores to metric robot performance. AToM-Bot received high human evaluations in need detection (6.42/7, 91.7%), embodied solution (6.15/7, 87.8%) and task execution (6.17/7, 88.1%). We show that AToM-Bot excels in generating and executing feasible plans to fulfill unspoken human needs.